
The linear feedback shift register is one of the most useful techniques for generating psuedo-random numbers. I’ve used this method for creating noise generators and as an element in the random modulation generators I spent a long time developing for my Protowave synth.
If you’re not really clear how an LFSR works, have a look at one of the many pages online (links below). This page isn’t here for that. In short, an LFSR takes a series of bits from a long shift register, XORs them together to come up with a resultant bit, shifts the register along one bit, and then sticks the new bit back into the beginning of the register. If the positions of the bits (the “taps”) are chosen carefully, this produces a maximal-length string of bits which is as damn near random as makes no odds to anyone other than mathematicians and cryptographers. For synth and audio use, it is easily good enough. A 32-bit LFSR will produce a sequence of over 4 billion random bits, or 500 million random bytes. If you output them as audio at 96KHz, the noise won’t repeat for an hour and a half. I think you’ll have forgotten what the beginning sounded like by then!
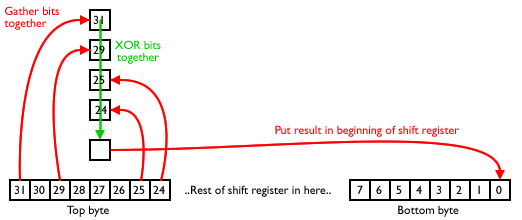
As an example, let’s take a 32-bit LFSR with four taps at positions 32, 30, 26, and 25. For some reason, LFSR taps are numbered starting on one, so take one off the tap position to get the bit that represents. So we need bits 31, 29, 25, and 24. It looks like this:
Here’s some PIC ASM code for our example LFSR:
; LFSR NOISE SOURCE ; Uses 5 bytes of memory: ; SHIFT_REG3, SHIFT_REG2, SHIFT_REG1, SHIFT_REG0, a 32-bit LFSR ; NOISETEMP is temporary storage during the calculation. ; NoiseSource: ;Get bits 31, 29, 25, and 24 for the feedback XOR ; Put Bit 31 into NOISETEMP bsf NOISETEMP, 0 ; Assume it's set btfss SHIFT_REG3, 7 bcf NOISETEMP, 0 ; Clear it if not ; Invert the NOISETEMP bit if Bit 29 is set btfsc SHIFT_REG3, 5 comf NOISETEMP, f ; Invert the NOISETEMP bit if Bit 25 is set btfsc SHIFT_REG3, 1 comf NOISETEMP, f ; Invert the NOISETEMP bit if Bit 24 is set btfsc SHIFT_REG3, 0 comf NOISETEMP, f ; Feedback is inverted wrt the XOR output bsf CARRY ; Assume it's set btfsc NOISETEMP, 0 bcf CARRY ; Clear it if not rlf SHIFT_REG0, f ; 32 bit shift rlf SHIFT_REG1, f rlf SHIFT_REG2, f rlf SHIFT_REG3, f ; A new random bit can be read from SHIFT_REG3,7 ; (or pretty much anywhere) return
This code is 16 instructions, if you ignore the return, and a similar number of instruction cycles.
The problem with the typical LFSR is that it only produces one new random bit each time you shift it. This is ok for some things (like my white noise source, but often you need a random 8-bit value (or on a dsPIC, a random 16-bit value). The obvious way to do this is to run the above code 8 times, which is ok, and works fine, but is very inefficient, since it’d need around 8×16=128 instruction cycles.
Instead, I started thinking about what happens when you run the code eight times, to see if I couldn’t get some gains from doing 8 stages of XORing and shifting at once. I’d been reading about Scott Dattalo’s vertical counters (Unfortunately Scott’s excellent website is no more) and this seemed like a logical thought.
To begin with, let’s just focus on tap 32. The first time we run the code, we pull out bit 31. The next time we run it, the register has shifted, so we pull out what was bit 30. The time after that, we get bit 29, etc etc. Over the eight runs, we get all of the bits of the top byte of the register.
A similar thing happens with each of the other taps. Tap 30 gives us a byte from bit 29 to bit 22, tap 26 a byte from bit 25 to bit 18, tap 25 from bit 24 to bit 17.
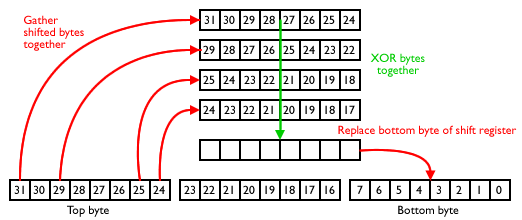
I realised that the more efficient way to perform the 8 sets of XORs is to take these four bytes and XOR them together as bytes rather than bit by bit. In order to do this, I have to shift the bytes in the register so that they all line up. We can then XOR, and finish up with a result byte which has all eight of the required bits for the front of the register in it. The final step is to shift the register over 8 bits. Since this is a one byte shift, we can use movf operations rather than eights sets of bitshifts with rlf. Again, this is much quicker.
Code for this looks something like this:
; LFSR NOISE SOURCE ; Uses 11 bytes of memory: ; SHIFT_REG3, SHIFT_REG2, SHIFT_REG1, SHIFT_REG0 ; NEW_REG0 The replacement SHIFT_REG0 byte ; TEMP_REG3A Exactly what they say on the tin. ; TEMP_REG3B ; TEMP_REG2A Temporary copies of REGs 2 & 3 ; TEMP_REG2B NoiseSource: ; First I need to copy two bytes I'm going to muck with movf SHIFT_REG3, w movwf TEMP_REG3A ; I need 2 copies for left/right shifts movwf TEMP_REG3B movwf NEW_REG0 ; Get bit 32 while we've got it movf SHIFT_REG2, w movwf TEMP_REG2A ; Two copies of this too movwf TEMP_REG2B ; Next, I need to XOR all the bytes together rlf TEMP_REG2A, f ; Left shift 1st set of copies rlf TEMP_REG3A, f rlf TEMP_REG2A, f rlf TEMP_REG3A, w xorwf NEW_REG0, f ; XOR with bit 30 rrf TEMP_REG3B, f ; Right shift 2nd set of copies rrf TEMP_REG2B, f movf TEMP_REG2B, w xorwf NEW_REG0, f ; XOR with bit 25 rrf TEMP_REG3B, f rrf TEMP_REG2B, w xorwf NEW_REG0, f ; XOR with bit 26 ; Perform a byte shift on the whole 32-bit register movf SHIFT_REG2, w ; Put SR2 into SR3 movwf SHIFT_REG3 movf SHIFT_REG1, w ; Put SR1 into SR2 movwf SHIFT_REG2 movf SHIFT_REG0, w ; Put SR0 into SR1 movwf SHIFT_REG1 movf NEW_REG0, w ; Put NEW_REG0 into SR0 movwf SHIFT_REG0 return
This is 27 instructions, ignoring the return, but does 8 times as much as the code above for only 10 instructions more. Certainly 27 is a lot better than 128.
Limitations and Possibilities
The only limitation is that you can’t use taps that are within the part that you replace in the final step. This is why I chose the set of taps 32, 30, 26, 25 and not the equally good 32, 30, 7, 4. Think what happens to those two low taps if we run the single-bit-shift version eight times – they get modified by new bits going into the register. My algorithm assumes this will not occur, so it only works with sets of taps where this assumption holds true.
This code is based on an arrangement known as the Fibonacci LFSR. There is an alternative arrangement called the Galois LFSR. This may offer a way to produce even more efficient code. I haven’t tried it.
Links
There seem to be lots of ways of looking at this, depending whether you’re coming at it from a hardware, software, or maths angle. It’s all the same really.
Wikipedia LFSR page – Wikipedia has a pretty good article on LFSRs, with details of the differences between the Fibonacci and Galois versions.
Xilinx – Useful application note with lists of maximal length XNOR tap sequences for registers from 3 to 168 bits in length.
EETimes, Tutorial on LFSRs – Another way of explaining the same thing. You might find this way is the way that makes the light come on for you.
Stumbled upon this while looking into random number generation on AVR. My Wikipedia-fueled understanding of the Galois LFSR is that it’s a bit more efficient than the Fibonacci version when doing single bit shifts, as it involves whole-byte XORs (just one XOR with your wisely chosen taps), but the improvement on your byte shifting algorithm would be minimal. And to work easily in that context, I’d imagine the Galois would need taps that are at least 8 bits apart and all 24>n>8 (N=32 is left out in Galois) or something like that. I have no idea if that’s even possible.
Your comment set me thinking about this again, and I think you’re right; the taps for a Galois LFSR would need to be 8 bits apart to make it work the same way. I was wondering if it isn’t possible to avoid this and to do only the “resultant” XOR, but I can’t currently see how. The idea would be that each XOR either inverts a bit or doesn’t – the final resultant state is therefore either inverted or not, depending on whether an odd or even number of inversions have been done over the eight cycles. Need to think about that more!
Nice one! Here’s a 31-bit random number (8bit) generator, same principle but with two taps (31,24), only uses 5 variables and 12 cycles.
RND31x8:
rlf rnd2,w
rlf rnd3,w
xorwf rnd2,w
movwf temp
movfw rnd2
movwf rnd3
movfw rnd1
movwf rnd2
movfw rnd0
movwf rnd1
movfw temp
movwf rnd0
return
best, mike from switzerland
That’s beautiful, Michael! Nice work!
Mike, I’ve used Tom’s routine very successfully, but like how small your code is. I’m wondering, however, if you mistyped the first instruction? Did you mean:
rlf rnd2,f
Otherwise that first instruction isn’t actually used. I haven’t had time to test this out since I just revisited this thread and saw your comment but am stuck at work for a while. Thanks!
Jared, no
rlf rnd2, w
is correct, used for the carry in to rnd3, and then aligning tap31 of rnd3 with tap 24 of rnd2, which must remain.
Hope you understand it now, it’s a bit confusing as the taps go from 1 to 32, not 0 to 31..
In fact, no need to shift (copy) the bytes, a simple 1-bit (noise) shift already generates the random bytes, with correct alignment.
expample RND15 tap 8: (temp will contain the random 8bits)
rlf rnd0,w
rlf rnd1,w
xorwf rnd0,w
movwf temp
rlf temp,w
rlf rnd0,f
rlf rnd1,f
I don’t understand what you’ve done here, or see how it might work.
If you only shift by one bit, but take a full byte out, you finish up with numbers that are no longer random, but rather heavily correlated. You can see this in the values as a “1” bit moves left increasing its value by two each time. If you plot the results, you get distinctive little exponential curves in the “random” data.
True, that last post (July 16, 2020) of mine was wrong.
I’m using the one from April 19, 2020 a lot, works fine.
64 bits at a time (for ARM Cortex-M0+):
#include
uint64_t prsg63(uint64_t lfsr) {
#if __ARM_ARCH_6M__
uint64_t tmp;
__asm__ (
“.syntax unified \n\t”
“lsrs %R1, %Q0, #30 \n\t”
“lsls %Q1, %R0, #2 \n\t”
“orrs %R1, %Q1 \n\t” // R1:__ = R0:Q0 << 2
"adds %Q1, %Q0, %Q0 \n\t"
"adcs %R0, %R0 \n\t" // R0:Q1 = R0:Q0 << 1
"eors %R0, %R1 \n\t" // R0 ^= R1
"lsrs %Q1, %R0, #30 \n\t"
"lsls %R1, %Q0, #2 \n\t"
"orrs %Q1, %R1 \n\t" // Q1:__ = Q0:R0 << 2
"adds %R1, %R0, %R0 \n\t"
"adcs %Q0, %Q0 \n\t" // Q0:R1 = Q0:R0 << 1
"eors %Q0, %Q1 " // Q0 ^= Q1
: "+l" (lfsr), "=&l" (tmp) ::); // R0:Q0, R1:Q1
#else
lfsr = lfsr << 32 | (lfsr<<1 ^ lfsr<> 32;
lfsr = lfsr << 32 | (lfsr<<1 ^ lfsr<> 32;
#endif
return lfsr;
}
With same spaced taps a-b and c-d we could xor only twice for the 1bit noise version.
For 8bits we need 2 xored bytes and xor them.
Example: LFSR taps 32-27-25-20
32 31 30 29 28 27 26 25
25 24 23 22 21 20 19 18
27 26 25 24 23 22 21 20
20 19 18 17 16 15 14 13
rrf b3,w
rrf b2,w
movwf t2
rrf b1,w
xorwf b2,w
movwf t1
movfw b3
xorwf t2,f
rrf t2,w
movwf t3
rrf t1,f
rrf t3,f
rrf t1,f
rrf t3,f
rrf t1,w
xorwf t2,f
movfw b2
movwf b3
movfw b1
movwf b2
movfw b0
movwf b1
movfw t2
movwf b0
return
That’s 24 cycles and 7 vars (4rnds & 3temps).
But we can do even better:
LFSR taps 32,25,22,15
32 31 30 29 28 27 26 25
22 21 20 19 18 17 16 15
25 24 23 22 21 20 19 18
15 14 13 12 11 10 9 8
rlf b0,w
rlf b1,w
movwf t1
rlf b2,w
movwf t2
rlf t1,f
rlf t2,f
movfw b3
xorwf t2,f
movfw b2
xorwf t1,f
rrf t2,w
rrf t1,f
movfw t2
xorwf t1,f
movfw b2
movwf b3
movfw b1
movwf b2
movfw b0
movwf b1
movfw t1
movwf b0
return
That’s 23 cycles and 6 vars (4rnds & 2temps).
best, michael